Earlier this year, we had four fantastic interns join our Algorithms team for 3 months to learn how we harness data science in our work at Stitch Fix. These four interns hail from across the country and spent their time exploring a specific project and advancing their skills in their unique interest areas. In their own words below, they’ve showcased each of their own projects and the meaningful insights they were able to uncover in their short time with us.
Optimizing inventory allocation for client-facing search
Maria Olaru, PhD candidate in Computational Neuroscience at University of California - San Francisco
In an effort to expand beyond its core business of Fixes, a service where stylists select five personalized items and send them straight to clients’ doors, Stitch Fix launched Freestyle. Freestyle is a personalized and instantly shoppable feed of items that clients can directly buy outside of their Fix. Within Freestyle, Stitch Fix recently launched a Search feature, allowing clients to directly query personalized items. I spent my time at Stitch Fix investigating how to optimize Stitch Fix’s existing inventory allocation to better serve customers who use Search within Freestyle to search for products. For my project, I chose inventory-related metrics to explore, collected the corresponding data, and compared these metrics to client satisfaction.
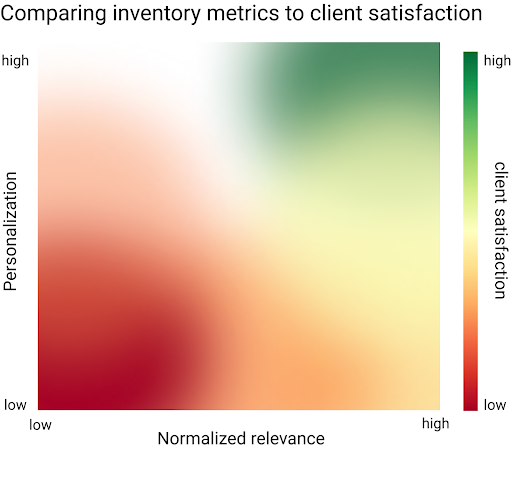
I chose inventory-related metrics that I could compare to client satisfaction: personalization and relevance. Personalization captures how well our items reflect clients’ individual style, while relevance captures accurately our items reflect what a client asked for. With Fix orders, we view personalization as a top metric that predicts client purchases. However, Freestyle differs from Fix in a crucial manner: clients using Fix are not asking for a specific item, whereas clients using Search within Freestyle know what they want, and are explicitly looking for it.
Next, I collected data for these metrics. To explore personalization and relevance in our archive of search queries, I built a search pipeline component that allows us to capture these metrics. However, relevance metrics are normalized within a single query, not across multiple queries. To compare relevance metrics across queries in a way that takes inventory fluctuations into account, I normalized the relevance of each query with respect to inventory availability.
Now that I had all the data I needed, I compared these metrics to client satisfaction. Using the observationally collected data, I found differing trends in how normalized relevance and personalization relate to client satisfaction. That being said, my findings may be confounded by when the customer searched for an item, or what the customer asked for. To investigate whether allocating existing inventory to optimize for these trends directly increases client satisfaction, stakeholders across the Algorithms and Product organizations are collaborating on an experimental proposal – stay tuned to see what they find!
Network Flow Optimization for Freestyle Client-Product Matching
Eric O’Neill PhD student in Chemical and Biological Engineering at Princeton University
I had the opportunity to work with the very talented Global Optimization team on a project related to inventory targeting for Freestyle. To make sure our items are seen by the people to whom they matter the most, and to provide an excellent personalized shopping experience, we solve a variation of the classic assignment problem. Solving the assignment problem seeks to make an optimal set of decisions that assign products to clients based on their corresponding ‘match score’: a cutting-edge internal prediction of how likely a client is to purchase an item if we show it to them. The assignment decisions are also subject to constraints on the number of items each client sees and inventory constraints to ensure we don’t over-assign items.
We can formulate and solve the assignment problem as a standard integer program (IP):
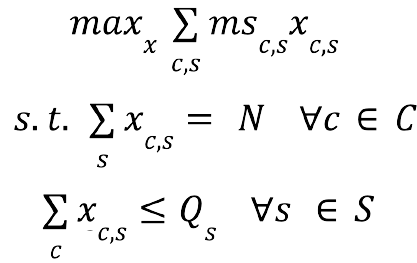
Where xc,s are our assignment variables, msc,s is the ‘match score’, Qs is the inventory, and N is our bound on the number of items to show a client. Indices c and s refer to clients and items respectively. Our objective is to maximize the expected sales. Generally, the solution time to solve an arbitrary IP using a standard solver like Gurobi/CPLEX scales poorly with the size of the problem. Solving the above inventory targeting problem using traditional solvers with the amount of clients and merchandise that Stitch Fix deals with quickly becomes computationally intractable.
Network flow algorithms to the rescue!
Special cases of the assignment problem can be re-framed and solved using polynomial time network flow algorithms such as the well known push-relabel algorithm [1]. To do this, we re-frame our problem as a directed graph G(V,A) with vertices V and arcs A and search for a ‘flow’ (an assignment of real values to the arcs) from the clients to the products that represent our assignment decisions.
I spent the bulk of my internship researching and implementing a generalized network flow algorithm called the Wallacher-Style GAP Canceling algorithm [2] that can handle the unique inventory constraint above that bounds expected sales by the product inventory. This constraint disqualifies some of the more popular maximum-flow algorithms because we are not able to work with integers in our graph representation. In addition, domain knowledge allowed me to develop problem-specific heuristics and warm start procedures that further improved the performance of the algorithm for our application. In the future, the fast solver for the Freestyle assignment problem that I developed will enable us to re-solve the problem as the inventory assortment changes to provide a better client experience and make sure every client sees the best in stock merchandise available.
References: [1] A V Goldberg and R E Tarjan. 1986. A new approach to the maximum flow problem. In Proceedings of the eighteenth annual ACM symposium on Theory of computing (STOC ‘86). Association for Computing Machinery, New York, NY, USA, 136–146. https://doi.org/10.1145/12130.12144 [2] Restrepo, M., Williamson, D.P. A simple GAP-canceling algorithm for the generalized maximum flow problem. Math. Program. 118, 47–74 (2009). https://doi.org/10.1007/s10107-007-0183-8
Style-level True Demand Forecasting
Pau Korpajarasoontorn, MS Analytics student at Georgia Institute of Technology
Stitch Fix relies heavily on algorithms to recommend styles that best match client’s preferences. However, the algorithms can’t perform at their best without proper inventory depth of each style. I worked with the Merch Algorithms team to build a style-level true demand forecasting model to assist their inventory purchase decisions.
Sales can only inform the censored demand because it is capped by inventory, but (true) demand isn’t. If we have experienced stockout and only rely on historical sales data for future inventory purchase decisions, we will be underestimating the true demand and suffer from lost sales. This is why we attempt to forecast demand instead of sales.
We divided this problem into two parts - demand imputation and demand forecasting. There is no ground truth to the demand imputation problem since we do not know the actual demand. We thus cannot apply the traditional supervised learning approach. We used a regression model instead to infer the true demand. Our regression model first estimates the impact of availability on censored demand controlling for seasonality. We then use the model to estimate the increase in demand had we maintained the target availability (the counterfactual). As shown in figure 1, the model works as desired - it imputes more when the style is within its selling season and the inventory availability is low.
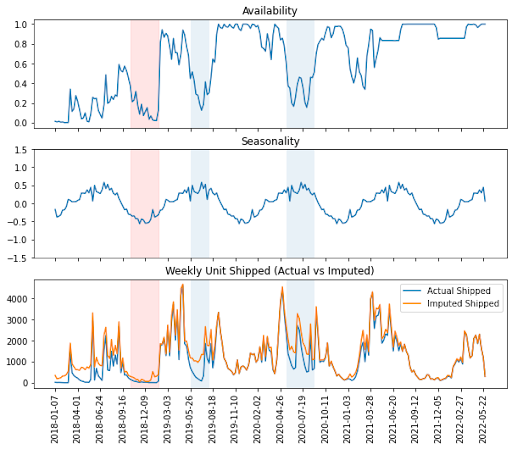
For demand forecasting, we adopted N-BEATS [1], a deep neural network architecture for interpretable time series forecasting. We use the imputed demand of all styles from the previous part as inputs to train the model. The model is trained to take 52-week lookback data and forecast 26-week demand. It beats the baseline forecasts by 18% and 8% on Mean Absolute Squared Error and Symmetric Mean Absolute Percentage Error, respectively. This project is an early attempt to explore true demand forecasting with state-of-the-art methods which also provides a framework for future improvement.
References: [1] Boris N. Oreshkin et al. “N-BEATS: Neural basis expansion analysis for in-terpretable time series forecasting”. In: International Conference on Learning Representations. 2020. url: https://openreview.net/forum?id=r1ecqn4YwB
Predict the Look @ SFIX – Trend-Level Analysis
Anna Dai, Master Student in Interdisciplinary Data Science at Duke University
Curating an inventory as great as our client base at scale is at the core of Stitch Fix’ success. Our Merchandising team work tirelessly to purchase and design the right pieces for our clients each season by referencing sophisticated algorithms built upon historical data as well as external research on fashion trends. As an intern on the Merchandising Algorithms team, I spent my time at Stitch Fix investigating how we can instead incorporate external fashion trends into our algorithms to better inform inventory purchasing decisions ahead of time and how viable that might be to implement.
For the scope of my internship, I had to first narrow down my goals. After speaking with various internal teams and external vendors to understand what trends data are currently being leveraged manually, I identified a number of viable data sources in both text-form and image-form and ultimately decided to pursue a natural language processing (NLP) approach due to the quality of data I could access. From here, I aimed to build a steel-thread attempt at quantifying these trend terms as measurable metrics of Stitch Fix inventory in order to facilitate further analysis. In other words, I wanted to answer: “To what extent is
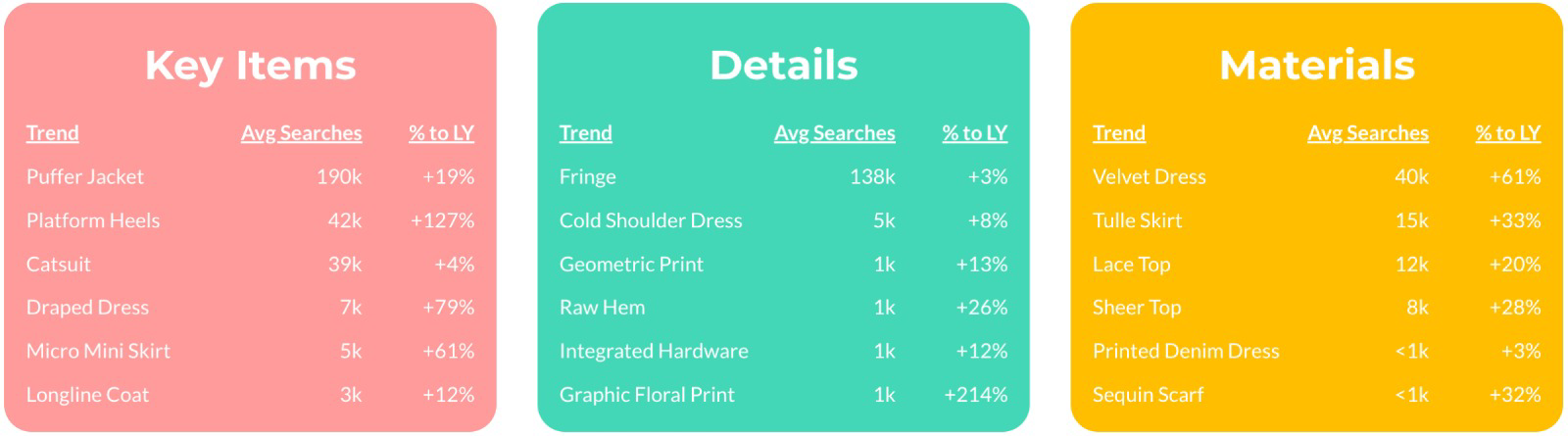
To begin, I pre-processed my data to extract a dataset of 758 unique terms related to women’s fashion in 2017 through 2022 as well as their trend predictions (i.e. “emerging”, “peaking”, “safe bets”, “declining”) from Trendalytics reports*. Next, I attempted different approaches to map these trend terms to Stitch Fix inventory. This mapping was particularly challenging because trend terms are diverse and ever-evolving, so we will not be able to construct a comprehensive list of all terms we might be interested in understanding. To address this, I had initially tried to pool inventory by existing attributes (i.e. color, material, silhouette) that most frequently occur in trend terms, but quickly realized that such static pooling would not be representative of most terms (e.g. white jeans might be trending but not white dresses, so we would run into too much noise if we pooled by color). Instead, I built dynamic pools of inventory that are associated with each trend term by tokenizing each term and projecting each token to the most-appropriate Stitch Fix attributes to filter upon through pre-trained word embeddings (i.e. Word2Vec[1], GloVe [2]). While this approach is highly effective for some terms, the limitations were also noticeable for our use case – “black” was close to “white” and “long-sleeve” was close to “short-sleeve” in these vector spaces so the projection scores were quite high for contrary terms.
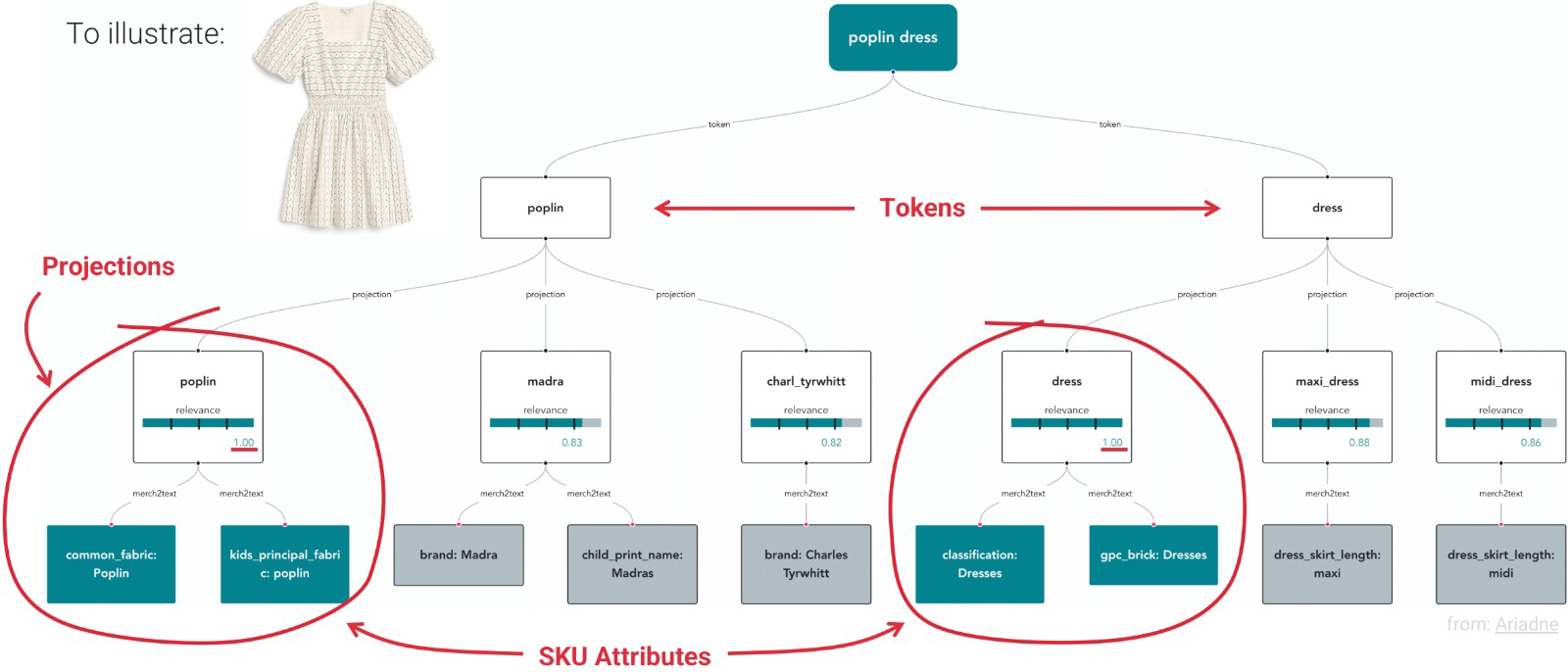
I decided to proceed only with terms that have near-perfect projection scores as “terms understood”. From here, I leveraged our newly deployed search functionality for Freestyle customers to identify the most relevant inventory for each search term. Several limitations of this implementation stem from the fundamentally different use case – trend analysis is more restrictive than search – as well as the non comparable relevance scores outputted from Elasticsearch (based on TF-IDF[3]), which I temporarily mitigated by heavily modifying the search pipeline to filter on each token and checking the final outputs against our existing latent style space. With the current implementation, my system was able to understand only around 30% and confidently map 10% of inputted trend terms, but the key advantage of the system is that it will continue to evolve automatically as our search functionality evolves, reducing duplicative work. From here, we open the door to trend-level analysis and modeling. Stay tuned for future work!
References: [1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space, 2013. [2] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: Global vectors for word representation. In Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, 2014. [3] KonradBeiske. Similarity in elasticsearch, Nov 2013. url: https://www.elastic.co/blog/found-similarity-in-elasticsearch