Personalizing fashion at scale requires that we build an inventory whose size and complexity are as great as that of our client base. To support our inventory expansion and our broader supply chain management, Stitch Fix has developed a suite of algorithms to act as a new inventory recommender system. In this blog post, we describe how we built this recommender system, from its data sources to its core models. Next, we describe the recommender system’s integrations across the supply chain, which range from augmented inventory curation, to AI-assisted design, to rapid vendor evaluation and onboarding for the Elevate Grant & Mentorship Program.
Building the Raw Materials for Personalization at Scale
Through the process of styling and collecting feedback, Stitch Fix builds expertise in matching inventory to clients. But we can only style items that already exist in our inventory. Inventory curation is therefore a fundamental component of our approach to supply chain management. But it is inherently difficult: fashion, as well as the tastes of our clients, are constantly evolving. And our client base is always growing. How do we go about curating an inventory of tens of millions of items, meant to serve an enormous and diverse client base?
We reasoned that if we could predict which items will perform well and with whom, we could greatly improve our merchandise investments. At the same time, these predictions could help us be more sustainable: clothing fabrication is resource-intensive, and data-driven purchasing can help us to avoid waste in the fabrication process, both internally and externally. To address these needs, we built a new merchandise recommender system, capable of accurately predicting merchandise performance across client segments. For simplicity, we will refer to this recommender system herein as ‘Style Explorer’.
Data and Data Pre-processing
In our modeling framework, we refer to each new piece of merchandise as ‘proto-merch’, in order to differentiate our candidate items from our existing inventory. In order to make inferences about a given piece of proto-merch, we first need to endow it with features. We make use of a wide range of feature types, from human-assigned categorical data, to photo imagery, to fabric attributes, to natural language. These data sources are developed independently across the organization, either by business partners or by research teams in our Algorithms group. In order for our featurization to be scalable in this context, we employ a series of custom ‘extenders’, each of which independently fetches attributes and then coerces them into a common data format.
Many of the most important merchandise attributes are things that might not be derivable from imagery. For example, what does the fabric feel like? At Stitch Fix these metadata are attributed by our buyers and the vendors they partner with. This places our buyers as a foundational part in creating a proto-merch’s digital fingerprint; it also provides us with a rich data source for our merchandise modeling efforts.
Another powerful feature set comes from our in-house computer vision service. Through the use of an ‘imagery extender’ we featurize high-quality proto-merch photo studio images. This allows us to standardize and measure a proto-merch’s color palette. But it also allows us to collect image embeddings, which can then be used to measure, for example, the similarity in fabric cuts between proto-merch and existing items in our inventory, for which we have extensive performance data. Finally, in order to measure an item’s immediate emotional resonance, we take advantage of client-item embeddings generated downstream of our Style Shuffle app. By inferring these embeddings, we gain valuable insights into the evolution in trends and in our clients’ preferences.
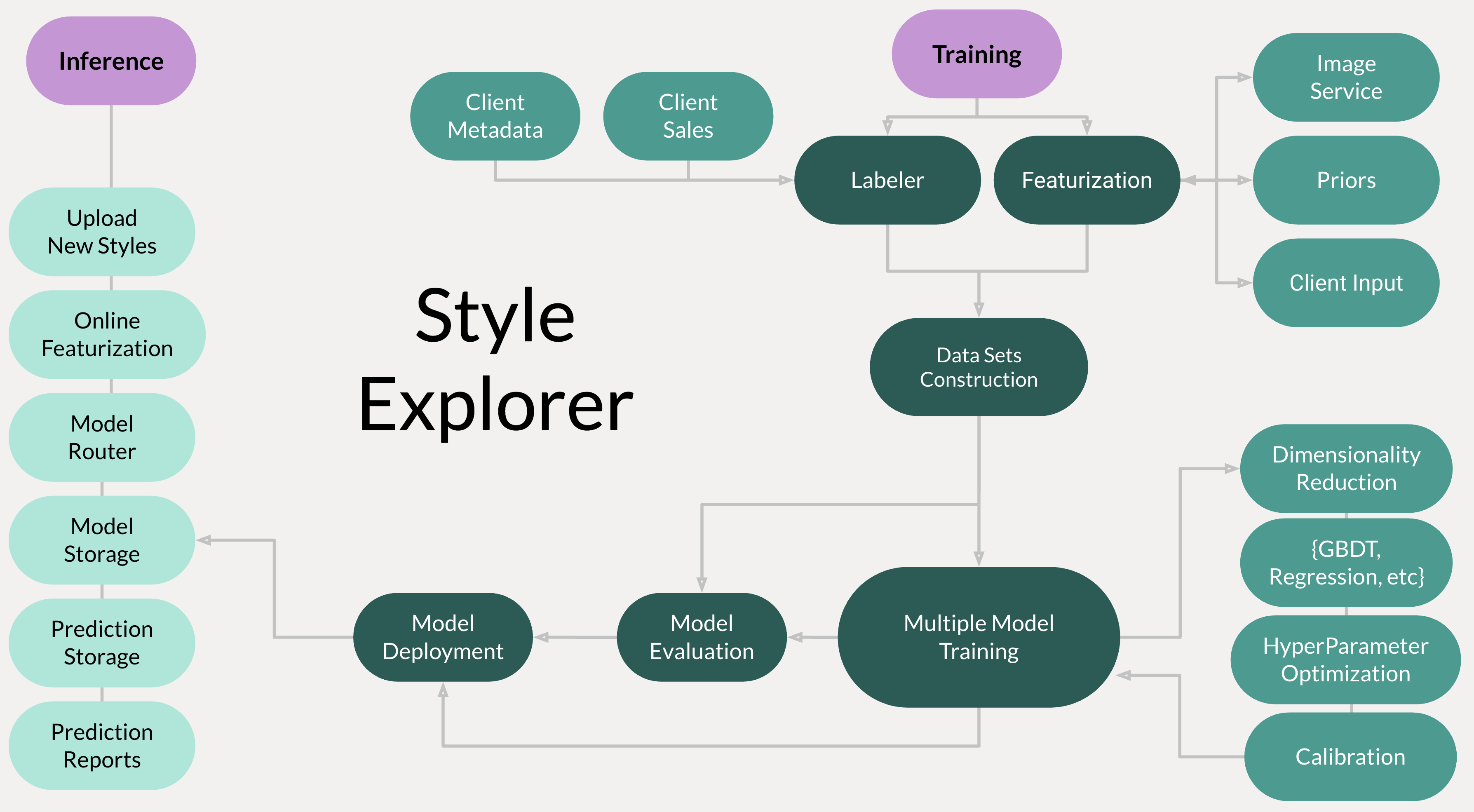
Above: The Style Explorer architecture. Training data is collected from independent data sources across our organization. Our featurized items then undergo a round of dimensionality reduction prior to model training. Before a model is deployed, we evaluate its performance as outlined below. Each model is then stored and routed to use-cases via a model management layer.
In total, our core models make use of over 500 features, tens of thousands of distinct styles, and tens of millions of client interactions. This feature space is extremely sparse, requiring that we reduce the dimensionality of our data prior to core model training. To reduce dimensionality, we use a lightly customized application of Uniform Manifold Approximation and Projection (UMAP), which we use to reduce from ~500 dimensions to 8. We use UMAP instead of approaches like LDA or t-SNE for its preservation of nearby distances in feature space, which corresponds neatly to our intuitive understanding of how different pieces of merchandise are related. For example, the difference between Rocker and Heritage is less important to model than the difference between blue plaid Heritage and green plaid Heritage. We then use this dimensionally-reduced dataset to train many different model architectures, each with optimized hyperparameters. This set of models is then scored with business-facing metrics (see below), such that different models can be productionized for different business use-cases.
Style Explorer Evaluation
Style Explorer’s performance is continuously and carefully evaluated, and this evaluation process requires significant oversight. The clearest justification for this time investment is that a model with poor performance could do significant harm to the business. But while this statement may seem obvious, it raises a series of questions whose answers are not. To shed light on why we think model evaluation is paramount in any machine learning project, and to guide others through this often-murky process, below we outline some of the questions we answer prior to model deployment.
To begin with, how do we select meaningful performance metrics? Traditional ML metrics such as mean squared error (MSE) may be simple to calculate, but for non-trivial use-cases they have critical flaws. Most importantly, MSE does not tell us anything about the threshold in modeling performance at which a model begins to add business value. Indeed, for some model-informed processes, an arbitrarily small MSE may introduce serious harm. For this reason, we strongly advocate for the use of custom, business-facing metrics instead of traditional ML metrics.
Secondly, in order to understand performance we need to understand the context our models might be deployed into. Style Explorer was primarily designed to augment inventory curation; to understand its impact we therefore need to understand how well our inventory is curated in the absence of model integration. While building this context is challenging, it also forces alignment between business partners and data scientists, which ultimately reduces investment in projects that will not be productionized.
Third, at what level of resolution should we evaluate a model’s performance? This is an important question because a model with strong top-line metrics may nonetheless have poor performance in specific areas. We are a growing company and are scaling out to more client segments and more business channels; thus, the number of decision processes and use-cases where we have a model deployed is growing rapidly. We therefore need a way to systematically and continuously monitor the decisions we are impacting–as well as the strategic importance of those decisions.
To address these issues, we make use of a model management layer, and prior to any model deployment we evaluate that model’s performance with custom, business-facing metrics. For Style Explorer, each metric is measured through a simulation of a commonly-encountered choice point in the actual buying process. In other words, our buyers make specific decisions about which prints, patterns, and silhouettes to buy, and we should evaluate our models in terms of how well they could make those same decisions. Below, we outline this process in detail.
Simulating the Buying Process
To summarize our approach to buying simulations, we ask how well our inventory would have performed over the last quarter, had we used buying recommendations from Style Explorer. We strongly advocate for this counterfactual approach, both for its ease of communication and for its alignment with the financial metrics business partners care about.
To be more specific in our approach, we first need to describe certain aspects of the buying process. The work of buyers is organized into what we call ‘merch nodes’, or specific subsets of our inventory. For example, one buyer may be responsible for ‘Men’s high price-point jeans’ and another may be responsible for ‘Women’s knit tops’. Within each merch node, buyers leverage their expertise and knowledge of trends to build an inventory that is both globally successful and focused on strategic company initiatives.
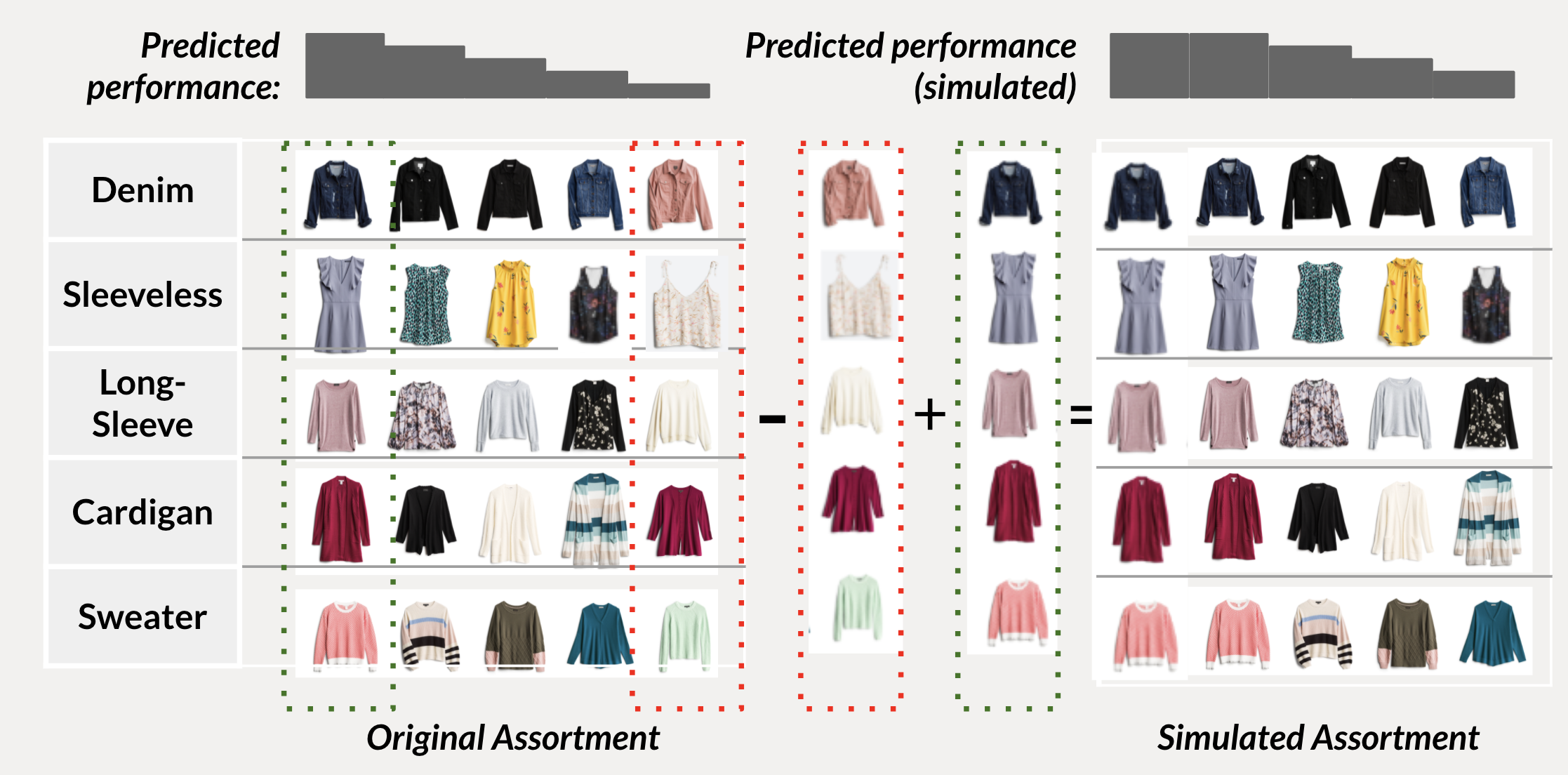
Above: an example simulated assortment. Within each ‘merch node’, Style Explorer predicts the performance of each item, ranks them, and then uses their ranks to determine how much volume of each item is purchased. Then performance metrics are calculated for the new, simulated inventory, and compared to the actual inventory.
After splitting our inventory into merch nodes, in each merch node we compute predicted success metrics for every item using Style Explorer. Then we use these predicted success metrics to virtually intervene in the buying process, for example by buying more volume of some items and less volume of others. Finally, we measure how this simulated inventory would have performed in terms of its overall success, revenue generated, and other key business metrics.
This intervention helps us to uncover merch nodes and specific decision points at which Style Explorer stands to add value. But it does not yet contextualize our modeling performance. To do that, we perform the above simulation a second time, but this time we move volume based on the actualized success of each item. Again we measure the performance of this new simulated merch node. In essence, this second intervention acts as a ‘crystal ball’ estimate, to give us a measurement of the ceiling of value we could add with a perfect model. By comparing these two estimates, we identify merch nodes where we have good predictive power; but we also find nodes where we are still far from the ceiling. These latter nodes generally offer good ROI for future modeling improvements, especially if the nodes cover a large merchandise volume or have high strategic importance for the company.
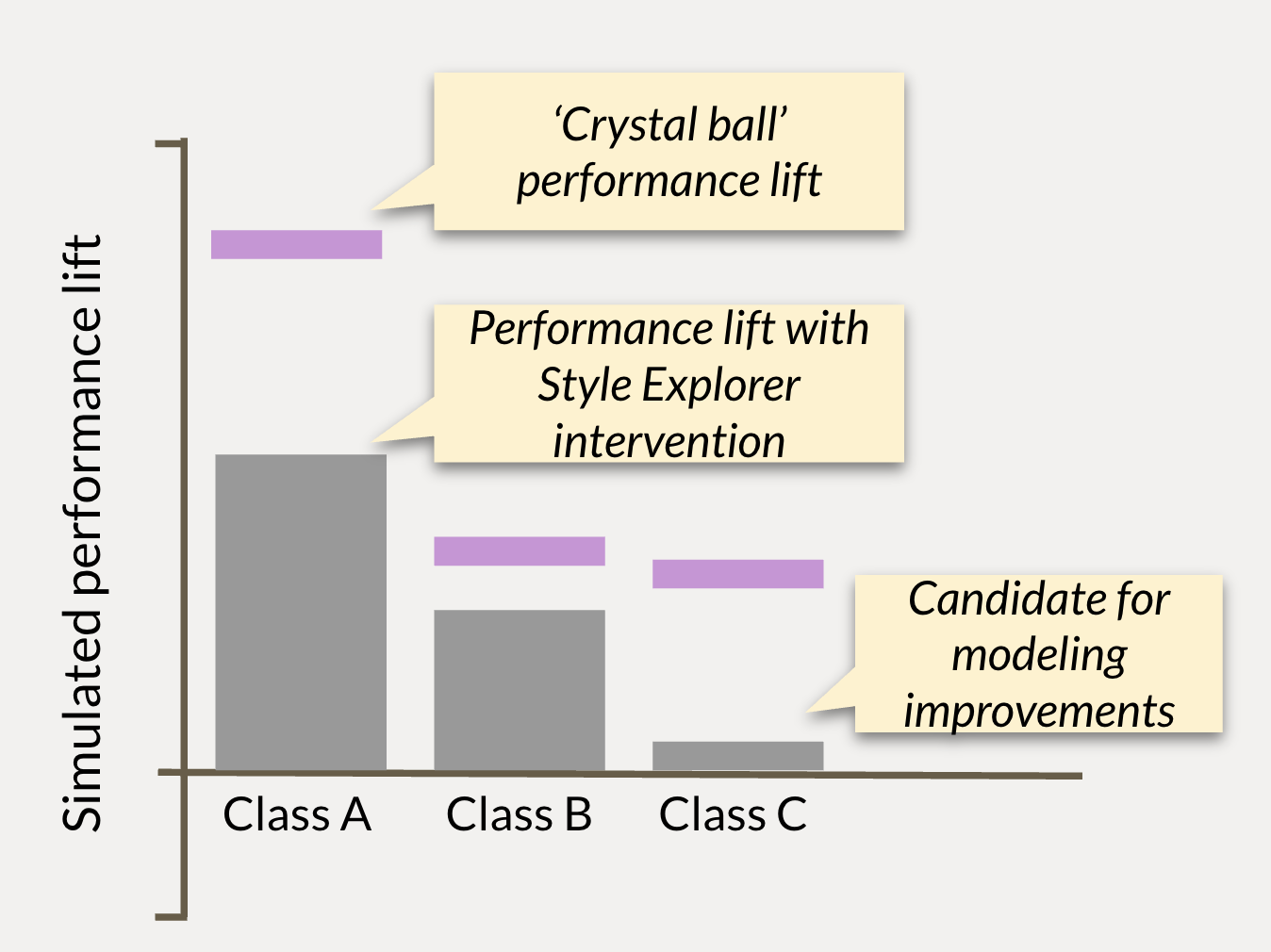
Above: For each class of item, we calculate performance metrics of simulated assortments. We compare these metrics to the outcome of simulations using a ‘perfect’ model to set a performance ceiling. Item classes like Class A where we see strong lift are good candidates for model deployment. Item classes like Class C, where we see only marginal lift but a high performance ceiling, are good candidates for further modeling improvement, for example through better featurization of the class.
The example given above is only the simplest type of inventory simulation, but it already approximates the constrained decisions made by our buyers. We can further extend these simulations to more specific questions, including ‘should I buy pattern X or Y’? And ‘which of these items best appeals to specific client segments?’ By performing this full set of simulations, we are therefore able to calculate realistic estimates of our modeling performance for specific use-cases. Importantly, these simulation metrics are capable of greatly differentiating the performance of models whose aggregate ML metrics are identical. Because of this fact, our simulation metrics are extremely important for model management, helping us to choose which model is productionized against which use case.
Integrations and Use-cases
Style Explorer’s item-level performance predictions can be leveraged as a data source by our Algorithms partners and as an actionable insight by our business partners. This gives Style Explorer extensive potential for integration, which can drive cross-functional collaboration and align incentives across business functions. Moreover, as Style Explorer is leveraged against more use-cases, any augmentation to its functionality will reverberate across each of Style Explorer’s points of integration. These qualities give Style Explorer outsize impact, and outline a roadmap to maximizing the value of Stitch Fix’s data science investments. For these reasons, we will close by highlighting several Style Explorer applications, emphasizing the architectural principles that make those applications possible.
Style Explorer for AI-assisted Design
In the traditional retail world, in order to understand how well an item will sell and with whom, that item needs to be designed, fabricated, quality controlled, distributed, racked, etc. In short, the feedback loop between design and sale for any new piece of merchandise is resource, time, and labor-intensive. It stands to reason then that if we could make early, AI-assisted design decisions, we could produce merchandise more sustainably, while reducing costs. At the same time, we could gain a competitive advantage with a reduced time to market. For these reasons, Stitch Fix is investing in Style Explorer for AI-assisted design.
In practice, our designers can use Style Explorer to iterate through combinations of cuts, prints, and patterns, and to ask which of those combinations will be successful. This approach not only enables AI-assisted design in the abstract sense; it allows us to use data to design clothes for specific markets or client segments. In other words, Style Explorer can be used to evaluate merchandise performance long before that merchandise has been fabricated, distributed, and sold.
Style Explorer for Vendors
Style Explorer’s core application is providing our buyers with predictions of merchandise success across different client segments. It therefore stands to reason that by extending these predictions to full portfolios of merchandise, we could use Style Explorer to distill themes around the ideal target markets for a given brand. Put differently, we could use Style Explorer to understand the impact of our vendors, i.e. the designers and makers of the merchandise we carry.
Taking this one step further, we might imagine these portfolio-level ‘Style Explorer Reports’ as having both internal and external-facing use-cases. For the internal-facing use-case, these reports could help us measure the impact of a new vendor in our ecosystem. For example, we could understand how much a vendor’s portfolio would expand our total assortment diversity or our penetration with a strategic client group. This information could then be used to drive decisions around which vendors we should onboard to help us meet specific growth targets.
In the external-facing use-case in contrast, Style Explorer Reports could be used to quickly build product-market fit reports for vendors, helping them to design sales, investment, and marketing strategies. In essence, these reports would act as a vendor value-added service, empowering outside vendors with our data science tools and helping them use data to drive the growth of their own businesses.
As one strong early validation for our vendor value-added service use-case, Style Explorer has been leveraged extensively for our Elevate Grant & Mentorship Program. This program was created to help grow, support, and mentor BIPOC-owned fashion companies. One motivating assumption for the program was that the traditional path between talent and success for designers and vendors may be inherently biased. If that is the case, then taking a data-driven approach to understanding product-market fit, as well as directly providing mentorship, financial backing, and advisory support, could establish a new and more direct path between talent and success.
As part of the Elevate Program, each of our Elevate grantees will partner closely with both the algorithms group and with our merchandising teams. As grantees design and iterate, we will use Style Explorer to continually evaluate the product-market fit for their portfolios. Thus, Style Explorer will be integrated into the feedback cycle of design, iteration, and strategic investment. This approach will help us to identify the best target markets for each of our grantees. Ultimately we hope that this use of Style Explorer as a vendor value-added service for our Elevate grantees will help grow their businesses and assortments. But by disrupting the traditional paths to success, we also hope to build a more equitable retail landscape.
Future Directions
Each use-case described above is capable of independently adding value. For example, our new merchandise recommender system will increase the power of our purchasing while improving sustainability in fabrication. Similarly, strategic vendor onboarding will help us to increase our penetration with priority client segments. But we believe that much of Style Explorer’s power is derived from its role as a core capability. For that reason, we will discuss future directions in light of Style Explorer’s integration across the supply chain.
One obvious benefit to wide integration comes from the fact that developing a new algorithmic capability is time and labor-intensive. Given this fact, it is clear that to justify data science investments we need to understand their potential to add business value. But it also becomes clear that the most efficient data science investments are the ones that can be leveraged widely. This consideration is paramount in both the design of our algorithmic systems and in how we understand the value of those systems.
A less obvious benefit of building core capabilities is that every small improvement is amplified across all other integrated systems. For example, if Style Explorer were only deployed for new merchandise recommendations, then a small improvement to the core model would have limited value. But because Style Explorer is widely deployed, that small improvement reverberates across Style Explorer’s other use-cases: it would increase the value of our vendor value-added services, and would improve our accuracy with AI-assisted design.
Finally, Style Explorer’s role as a core capability helps to drive alignment across our supply chain management systems. Our aim as a business is to personalize at scale, and that means investing in the new merchandise that will allow us to expand our total addressable market. But how do we serve new client groups if we don’t yet carry the merchandise to serve them? And similarly, is it advisable to buy new merchandise that does not appeal to our current clients? This chicken-and-egg problem requires an integrated solution: we need to invest in new merchandise and new client groups in parallel. Style Explorer, by informing the merchandise we buy and the vendors we partner with, always in terms of the clients we aim to serve, offers just such an integrated solution. In other words, Style Explorer acts much like a new outfit, helping us to realize the most authentic version of ourselves.